Performance Tuning
CodeTransEngine is specifically built to maximize speed of translating code (throughput). Its architecture is designed to handle multiple tasks concurrently, thanks to its non-blocking approach to inference and code execution. In simple terms, the Engine can juggle different tasks at the same time—such as running source code verifications while waiting for inference results, and vice versa. This dynamic “task balancing” doesn’t just happen within a single request; it works across multiple requests. As a result, the Engine achieves higher throughput and minimizes idle time on your hardware. That is especially valuable when benchmarking large language models (LLMs) for code translation in rented Cloud Computing instances that are billed per hour. This higher throughput means experiments can be completed faster and no resources are underutilized.
The Tree of Code Translations (ToCT) algorithm, which is used by CodeTransEngine, can sometimes be resource-intensive because it performs multiple inferences throughout the tree structure. However, the Engine allows users to adjust various parameters to control this process. These settings let you trade off between the thoroughness of the search (how exhaustive it is) and the speed of the translation. This flexibility ensures that the Engine can be optimized for different use cases and resource constraints.
At the same time, you can use CodeTransEngine without ToCT. For example when performing Direct Translation. This is the fastest way to translate code, but it may not always produce the best results. The Engine is designed to be flexible and to allow users to choose the best approach for their specific needs.
Performance Tuning Parameters for ToCT
Two of the most important parameters to tune are the number of intermediate languages and the number of intermediate translations in each path. These parameters allow to trafe-off accuracy and speed. The more intermediate languages and translations, the higher the chance of finding a translation, but the more computationally expensive the process becomes.
Number of Intermediate Languages
You can use our empirical results find what languages are most important to include for specific translation pairs. This is shown in the InterTrans paper. The higher the CA Decrease (%) in the Figure below, the more important it is keeping that language as intermediate.
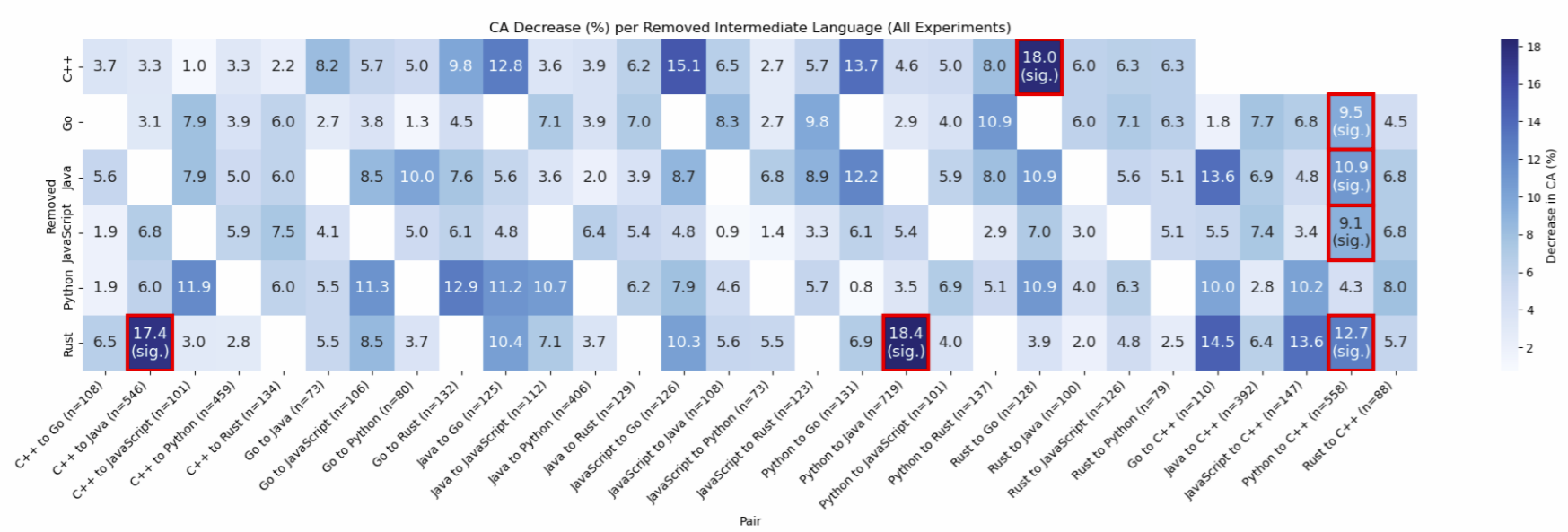
Depth of the Tree of Code Translations
The depth of the tree of code translations is the number of intermediate translations in each path. The more intermediate translations, the higher the chance of finding a translation, but the more computationally expensive the process becomes. A depth of 1 is equivalent to Direct Translation (ToCT is disabled).
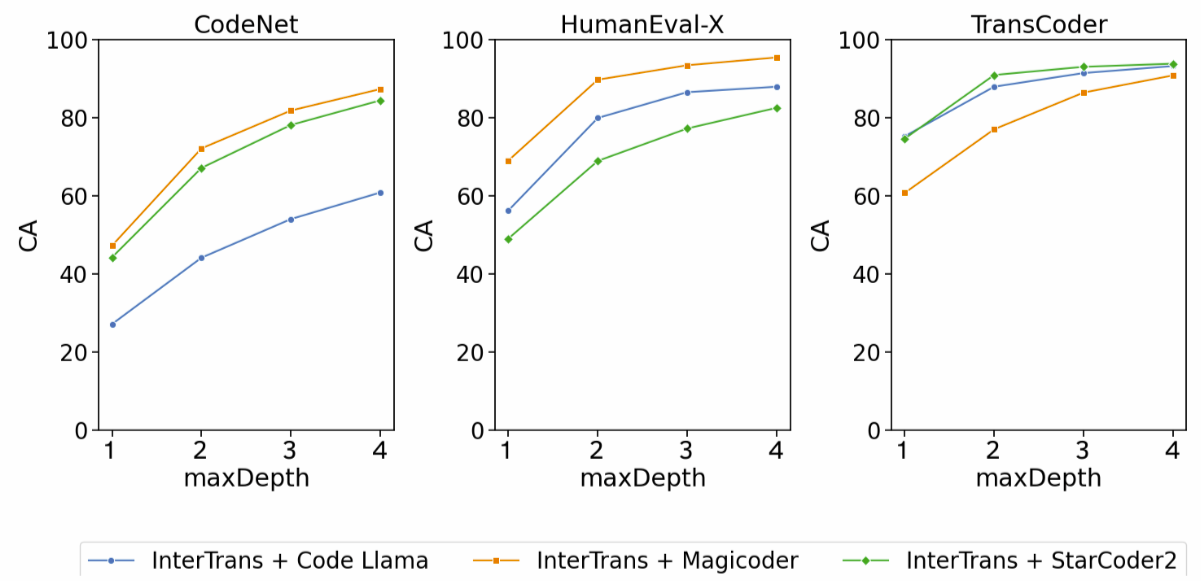
Our empirical experiments show that the Computational Accuracy (quality of translation) increases with the depth, but the gains after a depth of 3 start to show diminishing returns. Therefore, we recommend using a depth of 3 and use a depth of 4 only if you need to maximize the quality of the translation.
Algorithm-independent Parameters
The following parameters are independent of the ToCT algorithm and can be used to control the performance of the Engine:
useComputeEfficientMode: boolean
When set to true, it disables concurrency in InterTrans. This means that translations are processed sequentially and when there is an error in the path (e.g. can’t extract source code, or inference failed) the algorithm moves on to the next path. When a translation is found, the algorithm returns immediately. Setting this to false enables higher throughput and faster translations, at the expense of possibly additional computations. When set to false finding a translation in a path does best-effort stopping computations in other paths.
useInferenceCache: boolean
When an inference is to be performed for an edge, return a cached version if available if set to true. This should be set to false when looking to take advantage of randomness (such as performing Direct Translation @ K).
useResponseCache: boolean
When set to true it allows to cache the results of a translation request. This is useful to resume experiments or add new samples, as previous samples would not have to be recomputed (if other options remain unchanged)
useExecutionCache: boolean
If true, whenever the LLM generates a program that was previously seen, it returns the results of the previous execution for such program instead of executing it again
earlyStop: boolean
In translations where there are multiple test cases to be executed to assess the accuracy of the translation. When true if one of the test cases fails, the algorithm returns and does not execute the other test cases. false would execute all the test cases regardless if the previous one failed. Useful to disable when information about the status of each test case is necessary.